HiFi 测序技术原理是什么?
HiFi 测序即单分子实时测序(Single-Molecule, Real-Time Sequencing, SMRT)技术,该技术可针对数十千碱基及以上长度的长读长序列,实现单分子水平的超高测序准确度。HiFi 测序读段通过对单一 DNA 分子进行多次循环测序观测,整合多轮测序信息后生成,单条 HiFi 读段的碱基识别准确率可超过 99%。

该技术由太平洋生物科学公司(PacBio)研发,测序反应在特制的单分子实时测序芯片(SMRT Cell)上的微反应孔内完成,单片 SMRT Cell 集成数百万个此类纳米级微反应孔。HiFi 测序依托荧光信号检测实现 DNA 碱基及 DNA 修饰碱基的直接识别,且无需经过亚硫酸氢盐转化处理。在 DNA 聚合酶催化新链合成、向复制链中掺入核苷酸底物的过程中,会同步发射特异性荧光脉冲信号,通过实时捕获该信号完成碱基判读。此项核心技术为 PacBio HiFi 长读长测序平台提供了技术支撑,可产出高可靠性的长读长序列与高精度的测序数据。
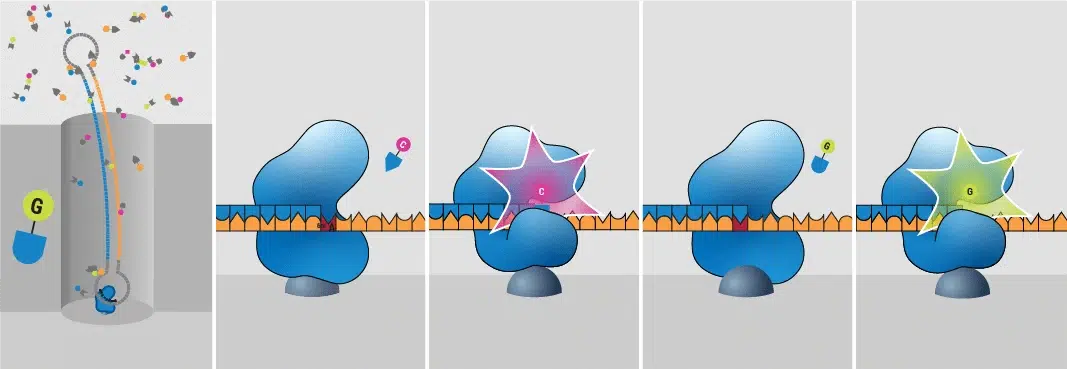
SMRT 测序有哪些优势?
长读长
近百 kb 的读取长度,可以轻松驾驭基因组的完整组装,以及全长转录本测序。SMRT 测序可提供出色的读长,而不影响通量或准确度。
数据来自经过片段筛选的 15 kb 人类基因组文库,使用 SMRTbell express template prep kit 2.0 建库试剂盒和 Sequel IIe 系统(2.0 版本测序试剂,Sequel IIe 系统软件 v10,30 小时测序时间)每个 SMRT Cell 的读长、read 数/数据以及其他测序性能结果因样本质量/类型和插入片段大小而异。

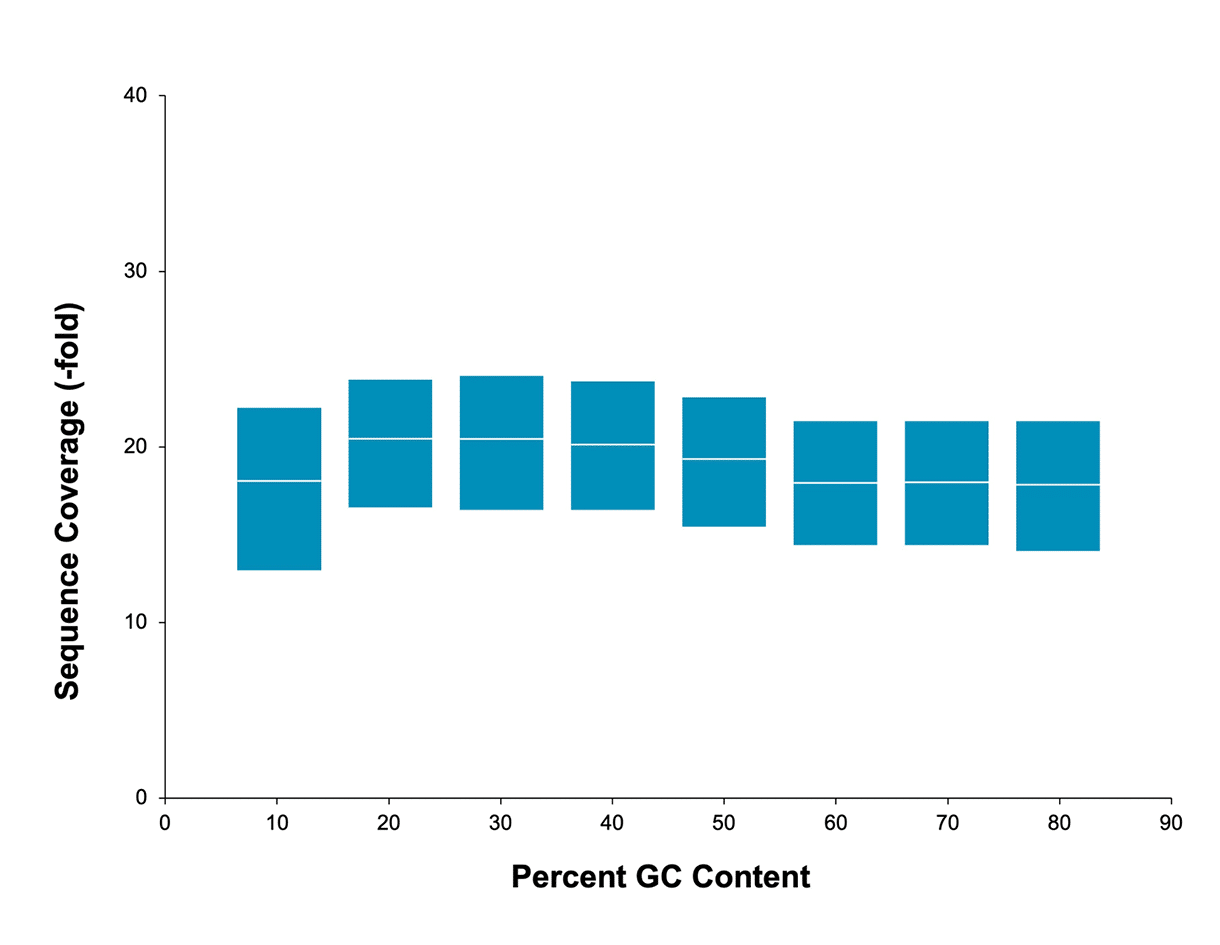
均一的基因组覆盖度
无 GC 碱基含量偏好性,可以对其他技术无法跨越的区域进行测序。使用 SMRT 测序,轻松检测富含 AT 或富含 GC 的区域、高度重复序列、长均聚物和回文序列。
人类样本中每个 GC 窗口的平均覆盖度。数据由 Sequel II 系统上的 20 kb HiFi 文库(2.0 版本测序试剂,Sequel II 系统)生成。每个 SMRT Cell 的读长、read 数/数据以及其他测序性能结果因样本质量/类型和插入片段大小而异。
表观遗传学
无 PCR 扩增流程,测序的同时直接捕获碱基修饰信息。通过测定 DNA 碱基掺入的聚合酶动力学变化,直接检测碱基修饰,无需化学修饰。在一次实验中即可采集到序列和表观遗传信息。

HiFi 测序原理常见问题解答
HiFi 测序提供一套精简的端到端工作流程,覆盖从样本处理到数据分析全环节。
首先使用 Nanobind DNA 提取试剂盒完成高分子量 DNA 提取,可在约两小时内从各类样本中获得高质量 DNA。随后通过手动或适配自动化平台的文库制备试剂盒,将 DNA 转化为SMRTbell 文库。
将文库上样至 Vega 或 Revio 测序系统,在 SMRT Link 软件中即可完成简便的运行设置。
测序完成后,依托由 NVIDIA GPU 加速的 Google Health DeepConsensus 等先进算法,系统将在机上完成数据处理,生成高准确度 HiFi 测序读长。测序结果以标准化 BAM 格式输出,可直接用于基因组组装、变异检测、单倍型定相及其他下游分析。
这套统一的工作流程降低了操作复杂度,加快科研结论的产出速度。
从 DNA 样本到 HiFi 读长生成的总时长通常为数天,具体耗时取决于应用场景与所用测序系统。
- DNA 提取:使用 Nanobind 试剂盒约需 2 小时
- 文库制备:约 1 天
- 测序运行:根据插入片段长度与系统(Vega/Revio)不同,耗时数小时至 1 天不等
- 数据处理:机上自动完成,测序结束后即可快速生成高准确度 HiFi 读长
由于 HiFi 读长准确度可达 Q30 以上,相较于其他长读长测序技术,其下游分析所需的校正步骤更少,助力研究者快速从原始 DNA 数据获得可落地的生物学研究结论。
测序结果以标准化BAM 格式输出,可直接用于基因组组装、变异检测、单倍型定相及其他下游分析。
HiFi 测序属于单分子实时(SMRT)测序技术,因此无需进行 PCR 扩增。该技术无需在测序前对 DNA 进行大量扩增,而是通过 DNA 聚合酶实时合成单条天然 DNA 分子,直接生成 HiFi 读长。
每个 DNA 片段会被构建为环形 SMRTbell 测序模板。测序过程中,聚合酶会围绕同一模板分子进行多次测序。通过 ** 环形一致性测序(CCS)** 整合多次重复测序数据,即可生成准确度达 Q30 以上的高精准 HiFi 读长,全程无需扩增。
规避 PCR 扩增具备多项优势:
- 减少扩增偏好性,GC 富集区或复杂区域的序列代表性更优
- 基因组覆盖度更均一
- 保留天然 DNA 的序列特征
- 直接检测碱基修饰
HiFi 测序通过多次测序的一致性序列实现高准确度,而非依赖扩增,在获得长读长、高准确度测序数据的同时,完整保留原始 DNA 分子的完整性。
HiFi 数据兼具长读长(通常 15–25 kb)与 Q30 以上高准确度的特点,可直接适配多种标准生物信息学分析流程:
- 从头基因组组装:获得高连续性组装结果,减少缺口,更完整解析重复序列区域
- 结构变异(SV)检测:精准识别大型插入、缺失、倒位及复杂重排变异
- 小变异检测(SNV 与插入缺失):高准确度可可靠检测单核苷酸变异及小片段插入缺失变异
- 单倍型定相:长读长可覆盖多个变异位点,实现大范围基因组区域的精准定相
- 全长转录组测序(Iso-Seq 分析):无需组装即可捕获完整转录本亚型
- 表观遗传修饰检测:天然 DNA 测序可直接检测碱基修饰
HiFi 读长可降低复杂基因组区域的分析模糊性,简化传统需结合杂交测序或大量验证的分析流程,加快从数据产出到生物学结论的研究进程。
